2. Topic Modeling with Gensim
2.1. Data
[1]:
%matplotlib inline
import matplotlib.pyplot as plt
from collections import defaultdict
from gensim import corpora
plt.style.use('seaborn')
documents = [
"Human machine interface for lab abc computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system",
"System and human system engineering testing of EPS",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
"Graph minors A survey",
]
# remove common words and tokenize
stoplist = set('for a of the and to in'.split())
texts = [
[word for word in document.lower().split() if word not in stoplist]
for document in documents
]
# remove words that appear only once
frequency = defaultdict(int)
for text in texts:
for token in text:
frequency[token] += 1
texts = [
[token for token in text if frequency[token] > 1]
for text in texts
]
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
2.2. Models
[2]:
from gensim import models
tfidf = models.TfidfModel(corpus)
corpus_tfidf = tfidf[corpus]
[3]:
lsi_model = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=2)
corpus_lsi = lsi_model[corpus_tfidf]
[4]:
lda_model = models.LdaModel(corpus, id2word=dictionary, num_topics=2)
corpus_lda = lda_model[corpus]
2.3. Document to Topic Membership
2.3.1. LSI
For LSI, you will have to cluster to see which documents go into which cluster.
[5]:
for doc, as_text in zip(corpus_lsi, documents):
print(doc, as_text)
[(0, 0.06600783396090049), (1, 0.5200703306361851)] Human machine interface for lab abc computer applications
[(0, 0.19667592859142102), (1, 0.7609563167700062)] A survey of user opinion of computer system response time
[(0, 0.0899263997244606), (1, 0.7241860626752509)] The EPS user interface management system
[(0, 0.07585847652177845), (1, 0.6320551586003429)] System and human system engineering testing of EPS
[(0, 0.10150299184979857), (1, 0.5737308483002964)] Relation of user perceived response time to error measurement
[(0, 0.7032108939378322), (1, -0.16115180214025474)] The generation of random binary unordered trees
[(0, 0.8774787673119844), (1, -0.16758906864659012)] The intersection graph of paths in trees
[(0, 0.9098624686818588), (1, -0.1408655362871859)] Graph minors IV Widths of trees and well quasi ordering
[(0, 0.6165825350569281), (1, 0.0539290756638969)] Graph minors A survey
2.3.1.1. k-means
When we use k-means, we supply the number of k as the number of topics. We may then get the predicted labels out for topic assignment. Note that this approach makes LSI a hard (not hard as in difficult, but hard as in only 1 topic per document) topic assignment approach.
[6]:
import numpy as np
from sklearn.cluster import KMeans
np.random.seed(37)
X = np.array([[tup[1] for tup in arr] for arr in corpus_lsi])
kmeans = KMeans(n_clusters=2, random_state=37).fit(X)
[7]:
kmeans.labels_
[7]:
array([1, 1, 1, 1, 1, 0, 0, 0, 0])
[8]:
kmeans.cluster_centers_
[8]:
array([[ 0.77678367, -0.10391933],
[ 0.10599433, 0.64219974]])
2.3.1.2. Plotting
[9]:
X = np.array([[tup[1] for tup in arr] for arr in corpus_lsi])
x = X[:,0]
y = X[:,1]
c = ['r' if i == 0 else 'g' for i in kmeans.labels_]
fig, ax = plt.subplots(figsize=(5, 5))
_ = ax.scatter(x, y, c=c)
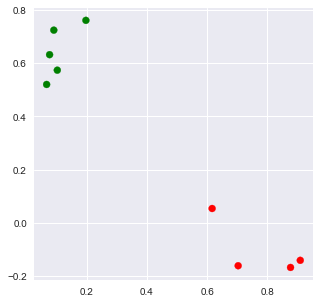
2.3.2. LDA
For LDA, the results gives you the probability of membership to each topic. Note these sum to 1.0 per document?
[10]:
for doc, as_text in zip(corpus_lda, documents):
print(doc, as_text)
[(0, 0.8609383), (1, 0.13906173)] Human machine interface for lab abc computer applications
[(0, 0.897828), (1, 0.10217202)] A survey of user opinion of computer system response time
[(0, 0.8827687), (1, 0.11723135)] The EPS user interface management system
[(0, 0.88589597), (1, 0.114104055)] System and human system engineering testing of EPS
[(0, 0.8546059), (1, 0.14539409)] Relation of user perceived response time to error measurement
[(0, 0.3230946), (1, 0.67690533)] The generation of random binary unordered trees
[(0, 0.19665903), (1, 0.803341)] The intersection graph of paths in trees
[(0, 0.14095493), (1, 0.8590451)] Graph minors IV Widths of trees and well quasi ordering
[(0, 0.13678026), (1, 0.86321974)] Graph minors A survey
2.3.2.1. Plotting
[11]:
X = np.array([[tup[1] for tup in arr] for arr in corpus_lda])
x = X[:,0]
y = X[:,1]
c = ['r' if np.argmax(X[r,:]) == 0 else 'g' for r in range(X.shape[0])]
fig, ax = plt.subplots(figsize=(5, 5))
_ = ax.scatter(x, y, c=c)
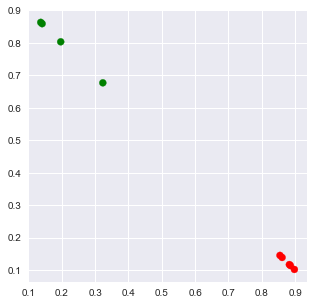
2.4. Id-Word and Word-Id
Knowing that IDs map to words (tokens) and vice-versa when we want to diagnose/troubleshoot how the weights associate with words within a topic.
[12]:
print(lsi_model.id2word.token2id)
{'computer': 0, 'human': 1, 'interface': 2, 'response': 3, 'survey': 4, 'system': 5, 'time': 6, 'user': 7, 'eps': 8, 'trees': 9, 'graph': 10, 'minors': 11}
[13]:
print(lsi_model.id2word.id2token)
{0: 'computer', 1: 'human', 2: 'interface', 3: 'response', 4: 'survey', 5: 'system', 6: 'time', 7: 'user', 8: 'eps', 9: 'trees', 10: 'graph', 11: 'minors'}
2.5. Word Weights or Probabilities
2.5.1. LSI
Each word has a sort of a weight associated with it per topic.
[14]:
lsi_model.get_topics()
[14]:
array([[ 0.04940859, 0.02969616, 0.03522417, 0.05951239, 0.1869311 ,
0.06135723, 0.05951239, 0.05823724, 0.03490897, 0.70321089,
0.53773148, 0.40171367],
[ 0.29287972, 0.2804038 , 0.32750471, 0.3204961 , 0.17065511,
0.46024666, 0.3204961 , 0.3726838 , 0.3323675 , -0.1611518 ,
-0.07585493, -0.0294099 ]])
2.5.1.1. Softmax Scaling
We may use softmax to transform the weights from LSI.
[15]:
from scipy.special import softmax
w = softmax(lsi_model.get_topics(), axis=1)
w
[15]:
array([[0.07084467, 0.06946182, 0.06984687, 0.0715641 , 0.08128912,
0.07169624, 0.0715641 , 0.0714729 , 0.06982486, 0.13622283,
0.11544712, 0.10076537],
[0.08833543, 0.08724021, 0.09144762, 0.09080894, 0.0781724 ,
0.10442909, 0.09080894, 0.09567389, 0.09189339, 0.05609854,
0.06109357, 0.06399799]])
[16]:
from wordcloud import WordCloud
def get_word_cloud_text(weights, id2token):
d = {f'{id2token[i]}': int(w * 100.0) for i, w in enumerate(weights)}
return d
def create_word_cloud(d):
wc = WordCloud(background_color='black')
wc.generate_from_frequencies(d)
return wc
def plot_word_cloud(w, id2token):
wc_texts = [get_word_cloud_text(w[r], id2token) for r in range(w.shape[0])]
clouds = [create_word_cloud(text) for text in wc_texts]
fig, axes = plt.subplots(1, 2, figsize=(20, 5))
for ax, cloud in zip(axes, clouds):
_ = ax.imshow(cloud, interpolation='bilinear')
_ = ax.grid(False)
_ = ax.axis('off')
plt.tight_layout()
[17]:
plot_word_cloud(w, lsi_model.id2word.id2token)

2.5.1.2. Min-Max Scaling with Adjustments To Negatives
Another way might be to assign zero to all negative numbers and then perform min-max scaling.
[18]:
from sklearn import preprocessing
w = lsi_model.get_topics().copy()
w[w < 0] = 0.0
w = preprocessing.minmax_scale(w.T).T
w
[18]:
array([[0.02926799, 0. , 0.0082077 , 0.04426959, 0.23345434,
0.04700873, 0.04426959, 0.04237633, 0.00773971, 1. ,
0.75430468, 0.55235244],
[0.63635383, 0.6092468 , 0.7115852 , 0.69635726, 0.37079055,
1. , 0.69635726, 0.80974798, 0.72215081, 0. ,
0. , 0. ]])
[19]:
plot_word_cloud(w, lsi_model.id2word.id2token)

2.5.2. LDA
The word weights per topics in LDA makes much more sense, as they must add to 1.0 per topic. These weights are probabilities.
[20]:
w = lda_model.get_topics()
w
[20]:
array([[0.0889305 , 0.09007747, 0.08601815, 0.08386292, 0.05002798,
0.15367272, 0.08598344, 0.11484789, 0.07876081, 0.07892839,
0.05578829, 0.03310144],
[0.04700249, 0.04509814, 0.05183834, 0.05541703, 0.11159794,
0.06927942, 0.05189603, 0.06885701, 0.06388869, 0.12849924,
0.16692205, 0.13970357]], dtype=float32)
[21]:
plot_word_cloud(w, lda_model.id2word.id2token)
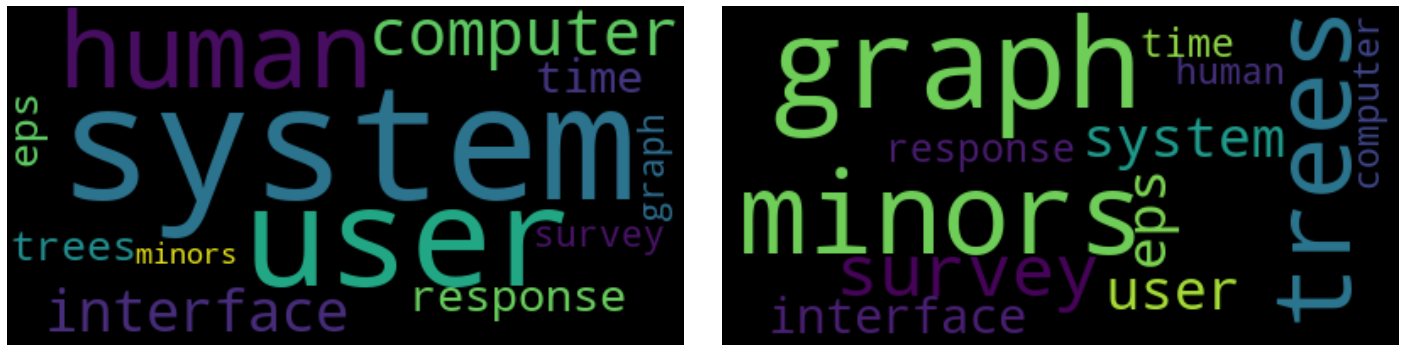
2.6. Coherence Scores
Topic coherence is a way to judge the quality of topics via a single quantitative, scalar value. There are many ways to compute the coherence score. For the u_mass and c_v options, a higher is always better. Note that u_mass is between -14 and 14 and c_v is between 0 and 1.
-14 <=
u_mass<= 140 <=
c_v<= 1
The coherence score is an aggregation of the following.
segmentation
probability estimation
confirmation measure
2.6.1. u_mass
Note with u_mass you always use corpus=corpus_<model>.
[22]:
from gensim.models.coherencemodel import CoherenceModel
cm = CoherenceModel(model=lsi_model, corpus=corpus_lsi, coherence='u_mass')
cm.get_coherence()
[22]:
-2.093259175449117
[23]:
cm = CoherenceModel(model=lda_model, corpus=corpus_lda, coherence='u_mass')
cm.get_coherence()
[23]:
-3.3492146807185965
2.6.2. c_v
Note with c_v you have to pass in the tokenized text texts=texts.
[24]:
cm = CoherenceModel(model=lsi_model, texts=texts, coherence='c_v')
cm.get_coherence()
[24]:
0.3838413553737203
[25]:
cm = CoherenceModel(model=lda_model, texts=texts, coherence='c_v')
cm.get_coherence()
[25]:
0.3838413553737203
2.6.3. Optimal Number of Topics
2.6.3.1. LSI
[26]:
import pandas as pd
results = []
for t in range(2, 10):
lsi_model = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=t)
corpus_lsi = lsi_model[corpus_tfidf]
cm = CoherenceModel(model=lsi_model, corpus=corpus_lsi, coherence='u_mass')
score = cm.get_coherence()
tup = t, score
results.append(tup)
results = pd.DataFrame(results, columns=['topic', 'score'])
[27]:
s = pd.Series(results.score.values, index=results.topic.values)
_ = s.plot()
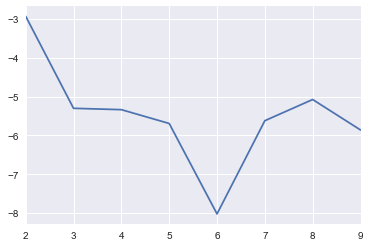
2.6.3.2. LDA
[28]:
results = []
for t in range(2, 10):
lda_model = models.LdaModel(corpus, id2word=dictionary, num_topics=t)
corpus_lda = lda_model[corpus]
cm = CoherenceModel(model=lda_model, corpus=corpus_lda, coherence='u_mass')
score = cm.get_coherence()
tup = t, score
results.append(tup)
results = pd.DataFrame(results, columns=['topic', 'score'])
[29]:
s = pd.Series(results.score.values, index=results.topic.values)
_ = s.plot()
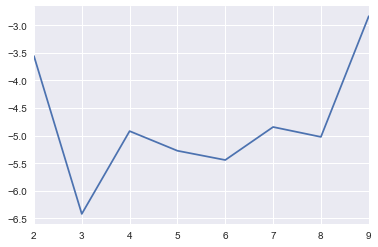
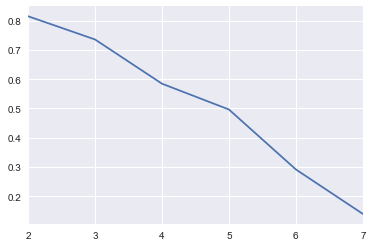
2.6.4. k-means
For LSI, we may also use k-means and the silhouette score. This score is between -1 and 1. A score towards -1 indicates bad clustering, a score towards 0 indicates mixed-quality clustering (bad and good, let’s suppose), and a score towards 1 indicates optimal clustering.
-1 <= silhouette score <= 1
[30]:
from sklearn.metrics import silhouette_score
results = []
for t in range(2, 8, 1):
lsi_model = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=t)
corpus_lsi = lsi_model[corpus_tfidf]
X = np.array([[tup[1] for tup in arr] for arr in corpus_lsi])
kmeans = KMeans(n_clusters=t, random_state=37).fit(X)
score = silhouette_score(X, kmeans.labels_)
tup = t, score
results.append(tup)
results = pd.DataFrame(results, columns=['topic', 'score'])
[31]:
s = pd.Series(results.score.values, index=results.topic.values)
_ = s.plot()